
Раньше на scomedy.com у меня был раздел с ютуб видео. Сайт на Drupal'е, поэтому особых проблем не возникло, просто создал дополнительный тип материала "YouTube videos" с полями title, description, youtube link, автоматическим генерированием превью, привязкой к нужным тегам, внутрисайтовым рейтингом и прочим. Т. е. по факту я получил тип материала, где основным контентом служил лишь один ютуб ролик. Тогда мне это казалось вполне себе хорошим ходом - а что, на сайте появилось с тысячу дополнительных страниц, на профилях комиков могу выводить топовые релейтид видео, которые доступны для просмотра прямо на сайте без перехода на ютуб, да и вообще наличие подборок видео явно не мешало, а наоборот хорошо вписывалось. Это я раньше так думал, потом раздел со всеми видео удалил, что, признаться, далось не легко, ибо на сабмит роликов убил далеко не один день. Но это все не суть важно.
Интересно другое. Перед тем, как удалить все видео, я прошелся по каждому из них. Вопрос, сколько из них "умерли" за примерно год после добавления? Порядка 25%. Двадцати пяти процентов! Т. е. если у меня было добавлено около 2к видео, то на сайте постепенно образовалось более 500 страниц с основным содержанием в виде битого ютуб ролика.
Это небольшое вступление - частный случай проблемы битых ссылок. Проблемы существующей и достаточно масштабной, на которую в большинстве случаев закрывают глаза.
Гипертекст же на то и гипер, что включает в себя ссылки на другие сайты и документы. А интернет среда живая и изменчивая, этим сайтам и документам свойственно "умирать", ну или переезжать без корректного редиректа. В результате - битые ссылки.
Масштаб, да. Т. е. если бы еще на уровне погрешности, то ничего. Но в отдельных случаях все куда более динамичней. Как в примере выше, где порядка четверти ссылок спустя год перестали быть валидными. Трудно назвать четверть погрешностью.
Или можно взять любой блог, открутить до постов n-летней давности, и пройтись по ссылкам из комментариев, например. Сколько будет живых? Половина? В лучшем случае. Хороша себе "погрешность".
И куда не посмотри, ситуация аналогичная. Где-то чуть лучше, где-то чуть хуже. Но все равно.
Возникает резонный вопрос, что делать? Я вижу три варианта.
1. Ничего
И если бы это касалось только сайтов "на коленке" и уютненьких бложиков. Так нет!
Википедия. Переходим на статью wikipedia.org/wiki/Bill_Hicks и кликаем по ссылкам из раздела References. Первая же выдает следующее:

Ок, не повезло, случайность. Попробуем другую статью, wikipedia.org/wiki/George_Carlin, и пройдемся по ссылкам в ней.
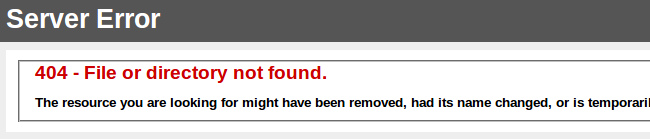
Эм, стало быть не случайность?
Вдогонку про недолгую жизнь ютуб роликов. Вот так обычно выглядит поисковая выдача тумблера, если в фильтрах поставить "искать только в видео":
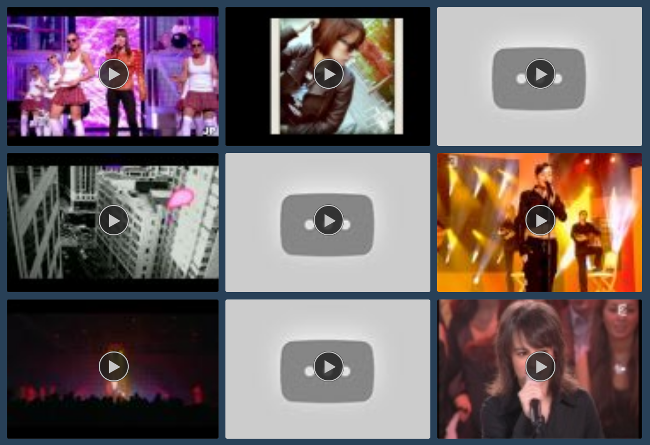
Хм, наверно есть сайты, где к валидности ссылок относятся достаточно рьяно. Например, каталоги сайтов. Основной контент и основная ценность у них - ссылки на другие сайты. Которые, по логике, должны быть валидными. Идем в дмоз и что видим? Да, достаточно ощутимый процент битых ссылок. Я уверен, что они регулярно проверяют все ссылки, но видимо как-то неспешно. На 58 ссылок из первой попавшейся категории "Writing and Editing" 7 битых, т. е. больше 10%.
Если даже "гиганты" не уделяют должного внимания проблеме битых ссылок, то что уж говорить о простых смертных. Впрочем, некоторые внимание иногда уделяют, например поисковые системы, так как если бы в серпе было 10-30% битых ссылок, то пользователи быстро перешли к конкурентам. Надо полагать, что и другие сайты начнут об этом задумываться, но тогда и только тогда, когда из-за битых ссылок (точнее, их процентного соотношения к валидным) начнет теряться аудитория и это уже будет вопросом выживания проекта, а не полезной фичей. Ну или если в команде проекта попадется перфекционист, еще не испорченный реалиями коммерческой разработки.
2. Не использовать внешние ссылки
Не-не-не, использовать ссылки на внешние ресурсы можно и нужно, и ровно в том объеме, в котором требуется. Просто бывают ситуации, когда этого можно избежать.
Например, не использовать хотлинки. Нужна картинка - надо взять и загрузить себе на сервер. Не всегда это возможно (иногда из-за копирайтов, иногда из-за технической реализации, т. е. если мы делаем поиск картинок в интернете, то всех их сохранять на наших серверах никакого места не хватит), но в большинстве случаев вполне себе вариант. Уже упомянутый выше тумблер при создании поста-картинки предлагает либо загрузить картинку с компьютера, либо указать url адрес. В последнем случае никакого хотлинкинга, картинка при сохранении будет автоматом загружена на сервера тумблера. Молодец, что сказать.
Или внешние скрипты, плагины и библиотеки. И ладно там jQuery, который можно подгружать с гугла (что, кстати, будет быстрее, нежели чем хранить этот фреймворк у себя на сервере - вероятность того, что пользователь до захода на ваш сайт был на каком-то сайте с подключенным jQuery достаточно велика, поэтому повторно библиотека грузиться не будет, а возьмется сразу из кэша браузера). Но вот всякие узкоспециализированные и не шибко популярные скрипты лучше хранить у себя. Пример - верстал сайт одному заказчику, и там уже была встроена достаточно сложная JS галерея, использующая стороннюю библиотеку. Перешел по ссылке, проект одного вебмастера. Поэтому не спрашивая разрешения просто залил эту библиотеку на сервер клиента и заменил пути в галерее на локальные. Что в итоге? В итоге проект с этой библиотекой умер уже через месяц (точнее, не умер, просто запретили удаленно подгружать ихние скрипы). Но клиента это ни в коей мере не коснулось.
И возвращаясь к Stand-Up Comedy Portal. Я все-таки хочу выводить список релейтид ютуб роликов на страницах с профилями. "Хардкодить" ссылки на отдельные ютуб ролики не вариант, ввиду их быстрой смертности. В результате я пришел к тому, что вполне себе решением будет ютуб галерея, куда на вход можно давать как id'шники нужных видео, так и id'шники плей листов, либо просто нужный нам search term. И чтобы при обращении к галерее по указанному ключу "на лету" вытягивались нужные ролики. И чтобы эти запросы шли со стороны клиента, а не сервера.
Т. е. объявление галереи должно быть примерно таким:
video idsearch termplaylist id
В случае с search term при каждом запросе страницы с ютуба запрашиваются релевантные ролики на данный момент, соответственно проблема с битыми ссылками будет снята (не совсем так, правда, т. к. надо еще самому фильтровать ролики, которые существуют, но в настройках которых запрещено встраивание на сторонние сайты).
Что удивительно, несмотря на кажущуюся тривиальность задачи, рабочих решений я так и не нашел. Поэтому начал "пилить" свою реализацию.
background: #EFEFEF;
border: 1px solid #DBDBDB;
padding: 5px;
position: relative;
}
#ysplayer-first {
position: absolute;
left: 0px;
}
#ysplayer-second {
position: absolute;
left: 853px;
}
#ysplayer-wrapper {
overflow: hidden;
position: relative;
}
#ys-status {
width: 100%;
height: 22px;
margin: 5px 0;
}
#ys-prev {
float: left;
width: 20px;
height: 22px;
background: url("/sites/default/files/other/ys-arrows.png") no-repeat 0 0;
}
#ys-prev:hover {
width: 20px;
height: 22px;
background: url("/sites/default/files/other/ys-arrows.png") 0 -22px;
}
#ys-next {
float: right;
width: 20px;
height: 22px;
background: url("/sites/default/files/other/ys-arrows.png") 20px 0;
}
#ys-next:hover {
width: 20px;
height: 22px;
background: url("/sites/default/files/other/ys-arrows.png") 20px -22px;
}
#ys-current-title {
float: left;
text-align: center;
font-family: Verana, sans-serif;
font-size: 16px;
line-height: 22px;
color:#333333;
}
#ys-previews-wrapper {
position: relative;
overflow: hidden;
height: 55px;
}
#ys-previews {
height: 55px;
position: absolute;
left: 0px;
overflow: hidden;
white-space: nowrap;
}
#ys-previews-title {
font-size: 14px;
height: 16px;
line-height: 16px;
font-style: italic;
color: #646464;
}
#ys-previews img {
display: inline-block;
white-space:normal;
width: 70px;
height: 52px;
margin-right: 5px;
opacity: 0.4;
margin-top: 3px;
}
#ys-previews img:last-of-type {
margin-right: 0;
}
#ys-previews img:hover {
opacity: 1;
margin-top: 0;
padding-bottom: 3px;
}
#ys-preview-arrows-left {
display: block;
float: left;
height: 64px;
line-height: 64px;
background: #D9D9D9;
}
#ys-preview-arrows-right {
display: block;
float: right;
height: 64px;
line-height: 64px;
background: #D9D9D9;
}
#ys-previews-scrollbar {
height: 10px;
width: 150px;
background: #FFFFFF;
position: absolute;
bottom: 0;
cursor: move;
}
- gXWqz5qWYEw
- mwhX5V1Gn6w
- 2mT1h_OXBNI
- _e698M9lYe0
- XPDEqUnNulg
- Ik5Nh94v7EQ
- 7PR3MvLVwdI
- wFbfY2TsFa0
- 4zgB1Jfpjdw
- ycekLtDDGnc
Это пока даже не набросок, а просто вариация на тему. Текущий код удалю и буду писать с нуля. Все оказалось не так просто. Под "не так просто" имеется ввиду, что я вообще не знаю JavaScript. Вообще. Я, конечно, об этом и раньше догадывался, но продолжал упорно писать код на JS "методом тыка" на базе мануала для новичков на w3shools. Но рано или поздно знаний должно было не хватить. Вот, не хватило. Поэтому сейчас дочитываю JavaScript: The Definitive Guide Дэвида Флэнагана (в Мозилле работает, кстати). И как только дочитаю, так и начну переписывать.
В идеале, должна получиться очень "вкусная" вещь. Функциональная, стабильная, кастомизируемая, с кучей фич. Будет опенсорсом, плюс выложу на github, а то аккаунт у меня там есть, но пустой. Не хорошо. Ну и хоть что-то полезное сделаю, да.
Вот собственно это ютуб слайдшоу пример того, как в некоторых случаях можно избежать использования кучи "вшитых" в код ссылок за счет альтернативного решения.
3. Проверять ссылки на "битость"
Есть ряд ссылок, надо проверить, есть ли среди них "битые", и если есть, то заменить их на новые или удалить. Вроде все логично и просто. Логично это да, а вот просто - не всегда.
Просто это когда. Когда, например, есть БД ютуб роликов, которые по крону публикуются в твиттер ленте. Надо только перед добавлением очередного твита проверять ролик на валидность (через YouTube API, полагаться на ответ сервера не приходится, т. к. ролик может существовать, но быть заблокированным, параллельно отдавая все тот же "200 ОК").
Или когда ссылка является на сайте отдельной сущностью, например полем "Homepage" в форме комментариев, тогда можно раз в месяц одним SQL запросом собирать все ссылки и проверять их на существование.
Но есть две проблемы.
Первая - а что делать с ссылками, которые могут быть где угодно? В теле комментариев, в статьях, просто "вшиты" в код... Первое, что приходит на ум - написать бота, который пройдет все страницы и проверит все ссылки. Собственно, идея не нова, и реализация таки существует: Online Broken Link Checker. Список их клиентов достаточно обширен: Microsoft, National Geographic, Time Out... Т. е. да, все-таки некоторые "топы" начинают расценивать битые ссылки как проблему, требующую решения. Бесплатно на сервисе можно проверять сайты в один поток, и не более 3к страниц с одного сайта.
Проверил этот блог, интересно же, сколько битых ссылок на сайте, где всего-навсего порядка двух сотен постов. Оказалось, что много - около сотни уникальных урлов больше не валидны, а если считать и дубли - то почти 500. В большинстве своем это ссылки из комментариев, но есть и ссылки в постах.
Сканировать время от времени все страницы, конечно, вариант. Но что если на сайте не 1000 страниц, а миллион? Это же какой сервер надо иметь, чтобы сайт обходом не положить. Но да, все-таки это проблема не проверки битых ссылок, а реализации этой проверки. Можно же и упростить, т. е. например если сайт использует БД, то просто делать дамп базы, и уже в нем искать вхождения ссылок, вместо того, чтобы каждую страницу запрашивать по http и грузить сервер. Решаемо, в общем.
Вторая проблема интересней и имеет уже не столь тривиальное решение. Что есть битая ссылка? В контексте все тех же ютуб роликов понятно, можно по АПИ узнать нужную нам информацию. Или там ссылка на twitter профиль или отдельный твит - если такого не существует, вернется 404 Not Found. Но что делать с обычными ссылками на сферический в вакууме сайт?
Упомянутый выше сервис поступает просто - полагается лишь на ответ сервера.

Решение "в лоб", да. И в данном случае другого не дано. Но это только частичное решение проблемы.
Под "битой" ссылкой понимается же не "любой ответ сервера, отличный от 200", а полная смена контента документа, при которой ссылаться на него в прежнем контексте уже нельзя. В такой трактовке сайт, который просто перестал существовать, будет лишь частным случаем.
Например, возьмем два домена - rlov.ru и flashmir.ru. Давным-давно они принадлежали мне и на них были даже какие-то проекты. Потом один сайт удалил, другой продал. На данный момент по первому адресу выдается приветствие "It works!" от nginx, а второй припаркован к Sedo. Битые ли это ссылки? А то! Но в обоих случаях - 200 OK.
Подобных примеров много. Когда на текущем домене уже не старый сайт, а совершенно новый ресурс или чья-то визитка, не имеющие никакого отношения к предыдущему проекту. Или дорвей. Ну или парковка, как в случае выше. И здесь уже проверкой ответа сервера не обойтись.
Единственным решением я вижу сравнивать текущее состояние документа по ссылке с состоянием документа на время публикации. Но как? Завести отдельную табличку в БД, куда автоматом загружать текст странички сайта при добавлении новой ссылки, и во время проверки проводить сравнение... Нет, слишком сложно, да и плохая портируемость.
Практически идеальным я вижу следующее решение. Тег может иметь глобальный атрибут title="" . И достаточно будет при добавлении каждой ссылки в этот атрибут прописывать содержание тега
того документа, на который ссылаемся. И во время обхода ссылок сначала проверять ответ сервера, и в случае с 200 OK уже сравнивать тайтл документа с тайтл атрибутом ссылки. Если есть расхождения - эту ссылку добавить в репорт для ручного просмотра. Сайт просто сменил название? Ок, обновляем значение атрибута. Если же сайт "умер" (заглушка, парковка, другой сайт) - ура, мы отловили битую ссылку.
Естественно, чтобы это заработало, надо потратить время на приведение всех существующих ссылок к нужному виду. И новые ссылки добавлять уже с учетом необходимости указания нужного нам title атрибута. Последнее, думается, можно реализовать технически на стороне сервера, т. е. ручной работы по заполнению атрибутов не будет. Идеально же.
Все это, конечно, хорошо. Но всплывает еще один вопрос. Уже, правда, не технический, а этический. Что делать с битыми ссылками?
Есть пост с подборками ссылок по теме, некоторые из которых "умерли". Удаляем их. Ок.
Есть статья, часть текста которой базируется на информации по внешней ссылке, которой больше не существует. Удаляем эту ссылку и контекст, в котором она существовала. Если последнее нарушает целостность информации, то контекст оставляем, ссылку делаем неактивной, добавляем пометку, что дескать ссылка больше не существует, не обессудьте. Как вариант.
Есть каталог сайтов, некоторые сайты перестали существовать, удаляем их без вопросов.
Есть статья, целиком и полностью подвязанная на внешний ресурс. Пост-ссылка, или пост, содержащий только ютуб-ролик. Удаляем? Так-то да. Но а что если к этой статье есть комментарии? Удалять вместе с ними? Ютуб вот трет комментарии, а реддит продолжает хранить посты, основанные на битых ссылках, даже если комментариев к ним нет.
Принятие решения становится еще сложнее, когда дело доходит до чистого UGC. Если контент создали мы, то мы и вправе его редактировать, переписывать или удалять. А если битая ссылка создана пользователем? Удалить ее и отредактировать сообщение? Сдается мне, что это совсем не вариант. Вариантом, видимо, тут будут только разнообразные "полумеры". Например, если ссылка в поле homepage комментатора перестала существовать, ее, наверно, можно и удалить (т. к. смысл в этой ссылке - узнать больше об авторе, а по битой ссылке многого не узнаешь). Если ссылка использовалась в тексте комментария, сообщении на форуме и в прочем UGC контенте, оставить ее, но сделать неактивной. Или в примере с тумблером (который при поиске выдает много битых видео) - посты пользователей не удалять, но и не выдавать в поиске. Ну и прочие вариации.
Да, не спорю, проблема битых ссылок может показаться надуманной и по большей степени прерогативой "сделаем интернетики лучше"-вебмастеров. Но иногда, все-таки, без этого не обойтись. Например, уже который год собираюсь делать каталог ресурсов по изучению английского (всего подряд - сайтов, сервисов, блогов, отдельных статей, языковых школ, книг, да даже твиттер аккаунтов и ютуб-каналов). И вот как-то не сильно хочется, чтобы через год половина ссылок стала битыми. А они станут. Если даже у дмоза с этим проблемы, при их-то системе набора модераторов. Поэтому на профилях ютуб-каналов буду использовать свое ютуб-слайдшоу, которое описывал выше, а не хардкодить ссылки на видео. А для просто ссылок использовать методику с title="" атрибутом. Что позволит минимизировать количество битых ссылок, держа их на уровне погрешности, но никак не 10-30%.
UPDATE
Хотел было написать в Google Webmasters, предложить добавить функцию показа битых ссылок на сайте, но они об этом видимо уже в курсе, судя по посту Мэтта Каттса What would you like to see from Webmaster Tools in 2014?
Some things that I could imagine people wanting:
...
Or almost as nice: tell the pages on your website that lead to 404s or broken links, so that site owners can fix their own broken links.
Было бы неплохо.
Комментарии
Маньяк друпальный =) За что же вы так все любите этот движок?
Друпал - нечто среднее между готовой системой управления контентом со строго ограниченным коробочным функционалом и программным фреймворком.
Т. е. одновременно два плюса - функционал ограничен только воображением разработчика (в пределах разумного, конечно) и при этом можно продолжать "программировать мышкой", т. е. собирать сайты с помощью "далее-далее".
Ну и до кучи грамотная политика руководства и адекватное сообщество (не без проблем и оплошностей, но в сравнении с аналогами грех жаловаться).