
Что мы хотим? А хотим мы полноценно работать с русским языком, т. е. чтобы не только русские символы нормально отображались (а не какими-нибудь вопросами или иными "кракозябрами"), но и чтобы полноценно функционировали все строковые функции.
Проводя параллели с PHP - как только возникает необходимость работать с кириллицей, сразу приходится отказываться от "чистых" строковых функций в пользу расширения mbstring.
Т. е. код
$ru = 'Да';
echo strlen($ru);
выведет на экран цифру 4. А вот это
mb_internal_encoding('UTF-8');
$ru = 'Да';
echo mb_strlen($ru);
даст нам уже ожидаемый результат в виде двойки.
В C++ все обстоит аналогично, а пример с php был токмо ради того, чтобы показать, что это дескать не си-проблема как таковая, и что все дальнейшие действия логичны и одинаковы для всех языков, только что реализация чуток различается. Ну и раз упомянул "все языки", то не грех сделать вставочку и про JavaScript.
JavaScript "цепляет" кодировку DOM'а. Т. е. при код
var ru = 'Да';
alert(ru.length);
выдаст нам двойку, а при мы получим уже, стало быть, четверку.
Кстати, кодировки - хороший пример того, что чем дальше в лес, тем толще партизаны. Т. е. чем ниже уровень языка, тем более явно и подробно надо прописывать что и как мы хотим использовать.
Возвращаясь к сям. Нам надо сделать следующее: установить нужную локаль, указать ее явное использование, работать с типами и функциями, поддерживающими мультибайтинг.
Установка локали
Как в Windows, не знаю, а в Linux все делается достаточно просто через консоль.
Какие локали уже установлены: locale -a Какие локали поддерживаются: less /usr/share/i18n/SUPPORTED
Нас интересует ru_RU.UTF-8, которая есть в листинге вывода второй команды, но которой скорее всего нет в выводе первой.
Если мы сидим под Debian, то проще всего включить нужную локаль будет командой:sudo dpkg-reconfigure locales
Нам выведется GUI, где и требуется отметить необходимый нам язык:
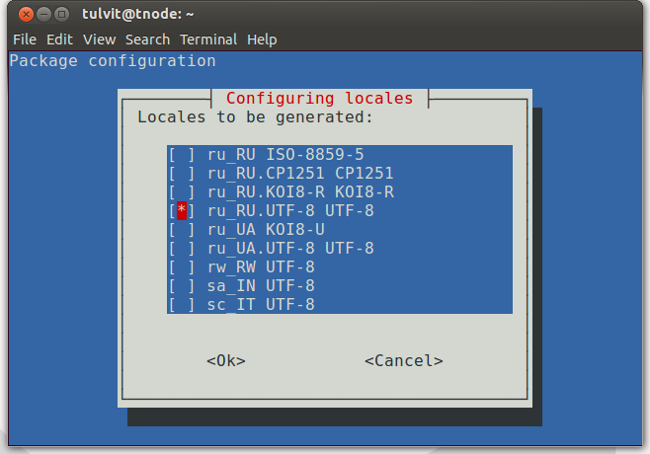
Для Ubuntu это уже не сработает, т. к. в ней команда dpkg-reconfigure locales просто тригеррит locale-gen без параметров и ничего более. Поэтому в Убунте для добавления локали используем следующую команду:sudo locale-gen ru_RU.UTF-8
После всего это требуемая локаль должна быть установлена, но на всякий случай проверяем ее наличие командой locale -a . Если вдруг нашей локали там почему-то нет, то пробуем выполнить следующее:sudo locale-gen sudo update-locale и опять проверяем.
Использование локали
Назначить использование локали в C++ можно двумя способами: либо с помощью функции setlocale() (но это больше C стиль, в плюс-плюсе может и не заработать), либо с помощью класса locale.
Данный код
std::locale::global(std::locale(""));
установит значение локали соответствующее локали окружения, в котором запускается программа. Но и назначить любую другую никто, конечно, не запрещает:
std::locale::global(std::locale("ru_RU.UTF-8"));
Кстати, для того, чтобы можно было работать с русским текстом в utf-8, технически можно указать и fr_FR.UTF-8, например. UTF он и во Франции UTF. А префикс "цепляет" именно локализованные особенности, как то формат вывода дат (где-то используется день/месяц/год, где-то месяц/день/год), разделитель порядков (опять же, может быть как "1, 000", так и "1. 000", в зависимости от страны), ну и так далее.
Использование мультибайтинга
Резонный вопрос, чем обычный char и string не устраивают? Дело в том, что char имеет фиксированную длину, ровно 1 байт. В UTF-8 тоже минимальная единица измерения - один байт. Но каждый символ может кодироваться последовательностью от одного до четырех байтов включительно. Конкретно русские символы кодируются двумя байтами.
Соответственно, чтобы закодировать один русский символ (2 байта в utf-8), нам потребуется взять два char (каждый по байту). И следовательно строка string ru = "Да"; будет иметь длину в 4 символа (по два на каждую букву). Что мы и наблюдали в примерах с php и JavaScript в самом начале.
Оно, конечно, не проблема, если мы работаем со строками как просто с текстовым массивом, т. е. там считать ввод и сохранить его куда-нибудь, вывести приветствие и так далее. Какая, собственно, разница сколькими там байтами что кодируется.
Однако, если мы хотим как-то работать с текстом, использовать строковые функции, обращаться к определенным символам, да хотя бы узнать длину строки - уже да, не вариант.
Здесь нам на помощь приходит тип wide character. Его char'овский аналог - wchar_t, а для string, соответственно, wstring (и да, если мы работает с "широкими" символами, то должны это учитывать везде, например cout'ом вывести wsting не получится, надо использовать wcout).
Т. е. wchar_t это как char, но с одной приятной для нас особенностью - если размер char'а строго один байт, то wchar_t имеет "плавающую" длину, и весит ровно столько, сколько требуется для хранения самого "большого" символа в текущей локали. Если наша платформа поддерживает только ASCII, то размер wchar_t будет как и у char, один байт. В случае же с utf-8, где один символ может кодироваться как одним байтом, так и четырьмя, wchar_t будет "весить" ровно 4 байта (т. е. максимально возможное для кодирования одного символа в utf-8). И вот тогда в один wchar_t спокойно влезет как любая буква, так и любой спец. символ.
А теперь соберем все вместе. Напишем очень сложную программу, которая считывает с ввода строку, и выводит ее обратно, но выводит посимвольно, что будет доказательством того, что и длину строки мы определяем, и к отдельным символам можем обращаться.
#include
int main() {
std::locale::global(std::locale("ru_RU.UTF-8"));
wstring input;
wcout << L"Введите строку:" << endl;
getline(wcin, input);
wcout << endl << L"Посимвольный вывод:" << endl;
for (unsigned int i = 0, l = input.length(); i < l; i++) {
wcout << input[i];
}
return 0;
}
Проверим, работает ли:
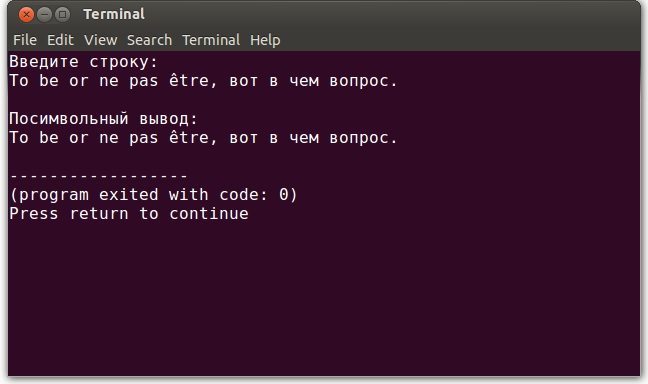
Работает!
И напоследок функция по конвертации string в wstring:
wstring str_to_wstr(string str) {
wstring wstr(str.size(), L' ');
wstr.resize(mbstowcs(&wstr[0], str.c_str(), str.size()));
return wstr;
}
Для работы этой функции надо подключить библиотеку Algorithms, #include .
"Костыль", да. Функции по конвертированию wstring в string на руках нет, надобности не было, сейчас попытался найти рабочее решение - сходу не получилось. Для чего вообще нужно конвертировать и почему нельзя использовать везде wstring? Не все нужные функции могут в wide string, например С++ MySQL Connector (для "сращивания" C++ и MySQL) - не может.
Вообще, стандарт C++11 имеет элегантное решение, однако на данный момент GCC не поддерживает необходимую для этого библиотеку.