
Google SafeSearch или так называемый "семейный поиск" - это фильтрация отдаваемого пользователю контента на предмет нецензурной лексики, излишней агрессии, адалта, разжигания разнообразных розней и тому подобного. Т. е. всего того, что может неблаготворно воздействовать на психику как детей, так и прочих божьих одуванчиков.
Так или иначе фильтрация контента используется на большинстве сервисов Гугла. На поиске - по умолчанию выключена. И более того, наличие "взрослого" контента никак не сказывается на позициях сайта в результатах выдачи. Если наиболее релевантный запросу документ содержит даже в теге title обсценную лексику - он все равно будет на первом месте. Аналогично и с поиском по картинкам. Однако чистый адалт тут, пожалуй, является исключением. Чтобы получить адалт выдачу недостаточно просто выключить фильтр, надо еще и ввести запрос, однозначно показывающий намерения пользователя (да хотя бы добавить "xxx" к запросу), в противном случае если запрос хоть и "взрослый", но может трактоваться двусмысленно, весь (или почти весь) адалт из выдачи вырезается.
Ютуб. Ролики фильтруются, а получить доступ к ним получится только зарегистрировавшись, и уже будучи под своей учетной записью согласившись на просмотр видео, которое "may be inappropriate for some users".
AdSense. Тут все жестче. Исходя из ихнего TOS, контекст вообще нельзя размещать на страницах с не "family friendly" содержанием.
Какой контент фильтруется? Если коротко - то весь. Медийка (аудио, видео, изображения) и текст. Точнее, не фильтруется, а потенциально может фильтроваться, что суть большая разница.
Аудио
Гугл давно имеет технологии по распознаванию речи. Голосовой поиск, например. Или автоматически сгенерированные сабтайтлы к ютуб-видео, "YouTube may use speech recognition technology to automatically make captions available". Чтобы найти видео с сабами (которые также можно автоматом переводить на любой язык) в Ютубе к поисковому запросу надо добавить параметр cc, например francoise hardy, cc. Ютуб генерирует сабтайтлы не для всех видео, конечно, а только для тех, для которых может выдать более или менее приемлемый результат. Попытка распознавания речи происходит сразу же после заливки ролика.
Может ли фильтроваться на базе этого видео? Да. Фильтруется ли? Нет. Я нашел небольшой ролик с распознанным аудио и безобидным видео рядом, но где через-слово-мат. Для незалогененных пользователей это видео заблокировано, но возможно "age restriction" было включено самим владельцем видео, либо же Ютубом, но не автоматически, а из-за репортов пользователей (под каждым видео есть пиктограмма флажка - пожаловаться на видео).
Теста ради залил на свой аккаунт два видео. Аудио первого содержит большое количество ненормативной лексики, и Ютуб распознал текст автоматически (показываются сабтайтлы). Второе видео содержит безобидное аудио, которое Ютуб не смог распознать, но я прикрепил к нему вручную созданные сабтайтлы, состоящие полностью из нецензурных слов. В итоге оба видео доступны для публичного просмотра без каких-либо ограничений. Странно.
Однако Ютуб все-таки автоматически анализирует аудио каждого ролика прежде чем сделать его доступным для публичного поиска. Но ограничения накладывает только на контент, защищенный авторскими правами. Взял видео клип, залил. Сразу же получил уведомление - так и так, "Ваше видео может содержать материалы, права или лицензия на которые принадлежат следующему лицу..." Ок, удалил из ролика аудио канал, перезалил. Нормально опубликовалось и попало в поиск. Стало быть фильтр был именно на аудио.
Видео
Я думаю, многие видели на Ютубе сию заглушку, или аналогичные:
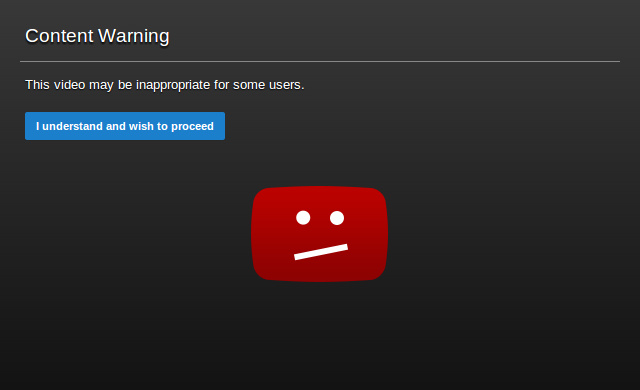
Т. е. да, то что фильтрует, сомнений не возникает. Вопрос в том, автоматически ли? Да, автоматически. Это же несложно. Имея в своем арсенале алгоритмы по анализу просто изображений, достаточно лишь нарезать видео на картинки и проверять уже их. И даже велосипед изобретать на надо, для работы с видео существует опенсорсное решение FFmpeg (статья на вики), которое Гугл и использует.
Кстати, для Ютуба вообще лишних телодвижений совершать не пришлось, надо полагать, нарезки там так и так создавались. Как для превью самого видео, так и "атласы" для работы всплывающих кадров при наведении мышки на таймлайн.
Возьмем какое-нибудь видео
И заглянем в DevTools во вкладочку Network. Помимо стандартных превью Ютуб подгрузил нам следующие атласы:


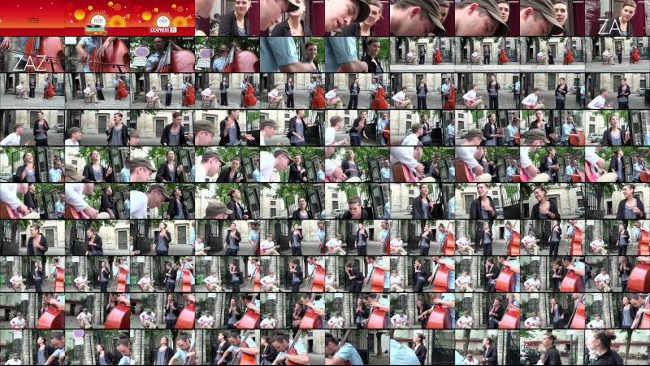
Этого, я думаю, вполне достаточно для того, чтобы сделать выводы о видео.
Впрочем, здесь такая же ситуация, как и с аудио, фильтруется только защищенный копирайтом материал.
Я залил на Ютуб несколько роликов, которые должны были зафильтроваться (не чистый адалт, скорее эротика, видео брал с того же Ютуба из тех, которые уже имеют статус age restricted, выкачивал их и перезаливал). Все видео попали в публичный поиск без ограничений.
В то же время, я взял ролик, защищенный авторскими правами (небольшое выступление одного из комиков, скачал на TPB). Сразу после заливки - "Ваше видео может содержать материалы..." и полная блокировка. Ок, может быть опять дело в аудио, как в примере выше? Удалил аудио, перезалил, и опять блокировка. Удалил аудио и сконвертировал в другой формат (из .flv в .mp4), залил. Блокировка. Вставил в начало ролика другой "безобидный" ролик (т. е. объединил два видео в одно) - и ура, никакой блокировки, видео доступно для публичного поиска, видимо по той причине, что в "атлас" уже не попали те кадры, на которые "триггерил" фильтр.
И все-таки вопрос, почему Ютуб автоматически не применяет фильтр на адалт содержимое роликов, остается открытым. Моя теория такова. Фильтр имеет некоторую погрешность, которая на объемах (а каждую минуту на Ютуб загружается по несколько часов видео) становится недопустимой, никакого штата в суппорте не хватит рассматривать каждую заявку на возможное ошибочное срабатывание робота.
Поэтому процесс происходит примерно так:
1. После заливки ролика аудио и видео анализируются на наличие нарушения копирайтов. Если нарушения есть - блокировка или фильтрация. Адалт и прочее если и анализируется, то никак на фильтрации не сказывается. Проверено (помимо того, что сам заливал ролики, некоторое время также мониторил и "последние добавленные" другими пользователями, а там уже попадался чистый адалт).
2. Дальше полагаемся исключительно на коллективное бессознательное, а именно на репорты пользователей. В случае с копирайтами это не будет работать, естественно, мало кто напишет "ой, а этот пользователь наверно не имеет прав на показ моего любимого клипа, заблокируйте его". Как только видео получает определенное количество "флагов", оно анализируется сначала автоматикой, а потом идет на ручную модерацию. Об этом Ютуб сам заявлял в одном из интервью, подчеркнув также и то, что пользователи из разных стран считают совершенно разный контент "неподходящим". Шокировать американцев каким-то злым роликом с использованием оружия вряд ли получится, например.
3. "Старые" ролики, не набравшие определенного количества показов (а следовательно которые и не могли получить "флаги" от пользователей даже при наличии "шок" контента) уже пропускаем через автоматические фильтры и блокируем. В этом случае даже при ложном срабатывании мы не получим шквала недовольства от пользователей - мало кто следит за своими роликами несколько месячной давности с двумя показами, скорее всего и сам аккаунт уже заброшен. Но это лишь мое предположение, основанное на том, что если покопаться в архивах Ютуба, то никакого адалта найти не получится. Значит, все-таки, выпиливают.
Ок, с Ютубом разобрались, а как обстоит дело с видео с других сайтов? Индексирует ли их Гугл? Индексирует. Идем в Гугл поиск по видео и видим, что видео цепляются с совершенно разных сайтов:
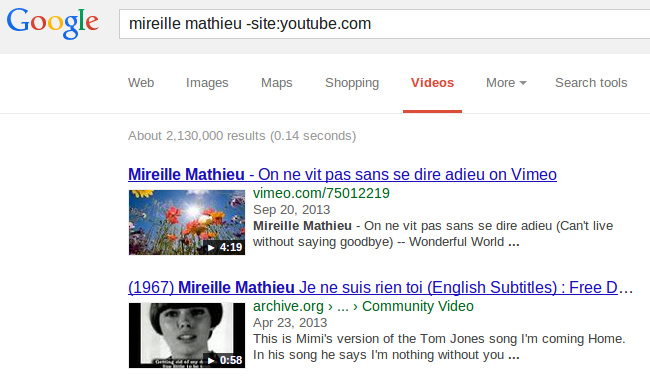
Помимо ссылки на видео и сниппета, нам показывается превью видео и его длительность. А значит Ютуб прогнал его через упомянутый выше FFmpeg. Следовательно и "атласы" для фильтрации для себя сохранил. И, скорее всего, лишнее отфильтровал. Я пытался найти хоть одно адалт видео при включенном SafeSearch, не смог.
Изображения
Анализирует и пытается фильтровать все изображения. Это хорошо заметно по адалт запросам (с/без фильтра выдача сильно разная), в меньшей степени фильтруется "шок-контент" (dead body и прочее, видимо сложнее выявить).
С этим все понятно, но интересна одна особенность именно по адалту. Под не family friendly подпадает не только явный адалт, но и "намерения". Т. е. фотография одетого человека в "нескромной" позе будет уже адалтом. Или другой пример - фотография модели в нижнем белье в каталоге этого самого белья это не адалт. А вот та же модель, в том же белье, но в мужском журнале - уже адалт. Ибо те самые "намерения" и контекст уже другие. Естественно, такие мелочи роботу не распознать, поэтому проще для сервиса поиска по картинкам допускать достаточно большую погрешность, а сайты в АдСенсе просматривать силами модераторов вручную, если робот посчитал картинки на нем подозрительными.
Точнее как это происходит, робот обнаруживает на сайте картинки, которые расценивает как неподходящие, об этом АдСенс паблишер получает уведомление и срок в три дня на исправление. Если по прошествии времени (не обязательно озвученные три дня, иногда вплоть до нескольких недель) нарушения остались, сайт блокируется, но у вебмастера есть возможность подать апелляцию. И вот эту апелляцию и сам сайт уже будет смотреть не робот, а живой человек, который и определит, было ли "намерение" или нет. Вопрос скользкий, да, и редко кому удается убедить суппорт в ошибочном срабатывании автоматики:
– Какой это адалт? Это же фоточки пляжей с отдыхающими людьми, в чем они должны еще быть, как не в купальниках?
– Ок-ок, но вот те люди на заднем плане позируют слишком вызывающе, так что все-таки адалт, не иначе.
Текст
Понятное дело, что при включенном SafeSeach Гугл не позволит вбивать поисковые фразы, состоящие исключительно из нецензурщины:
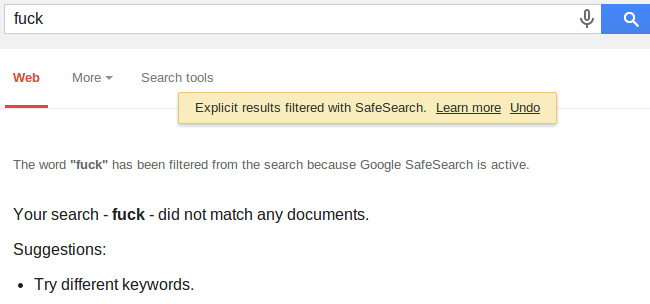
Однако чуток изменим запрос, и уже получаем выдачу, пускай и отфильтрованную:
Сразу достаточно важное отступление: использование нецензурных слов не запрещается. Запрещается их чрезмерное употребление. В Policy АдСенса так и прописано, не "profanity", а "excessive profanity". Т. е. вставить изредка ругательство - ок. Использовать мат заместо пунктуации - уже нет, не ок.
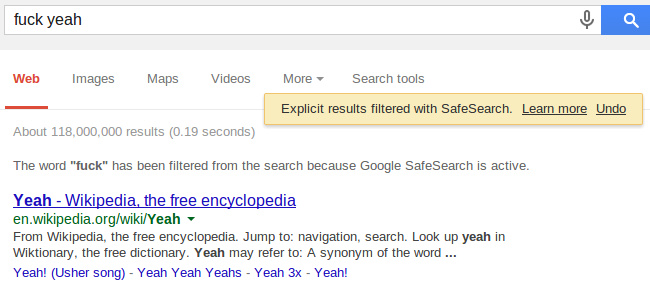
Не отходя от кассы, проверим как это работает. Включаем SafeSearch и загуглим что-нибудь безобидное:
Как видим, топ-2 занимает сайт со словом "fuck" в заголовке. Это, стало быть, нормально. Или вот еще пример:
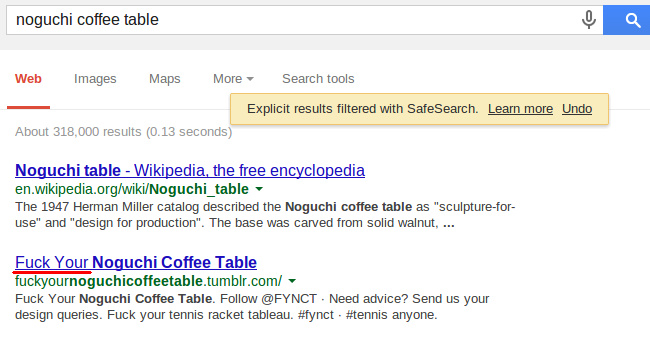
И это тоже нормально, да.
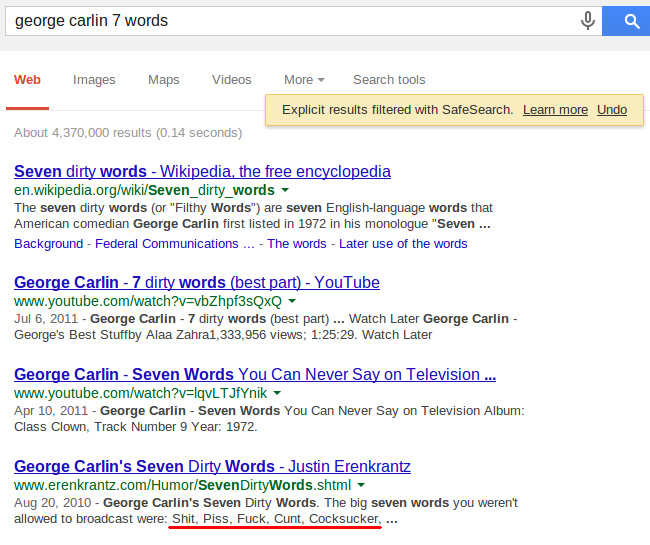
Теперь перейдем к поиску по сайтам, которые таки мат-заместо-пунктуации. Какую мы видим выдачу с отключенным SafeSearch:
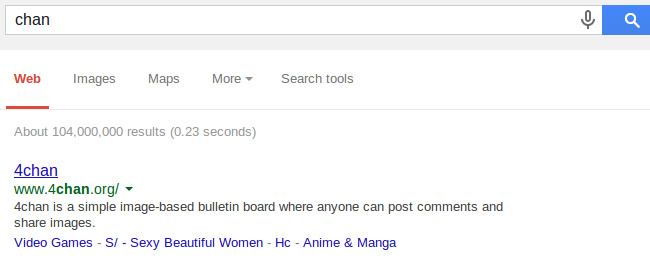
И с включенным:
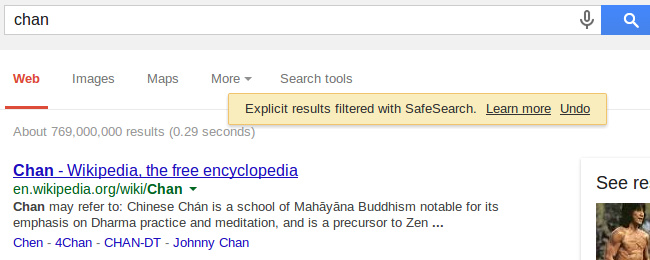
При обычном поиске 4chan у нас на первом месте, при безопасном - нет такого сайта, только статья на вики. Вполне логично.
Еще возникает закономерный вопрос, фильтруется весь сайт или же только страницы сайта? В примере выше (с 4chan) видно, что зафильтровалась главная страница сайта, хотя она вполне себе безобидная, т. е. некоторые страницы сайта (чистые сами по себе) могут фильтроваться на базе наложенного фильтра на другие страницы. Вполне возможно, что наличие ссылки на небезопасную страницу также является одним из факторов.
Но могут, конечно, фильтроваться и только отдельные страницы. Возьмем страницу с цитатами относительно "чистого" комика.
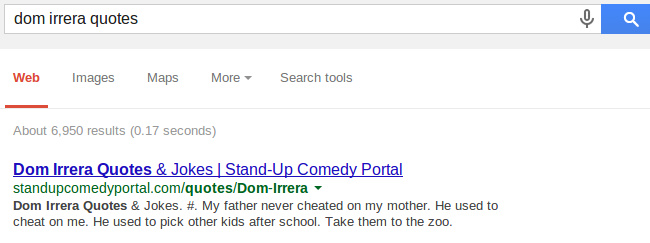
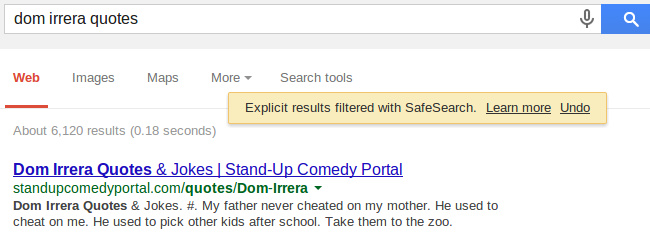
Что без фильтра, что с фильтром мой сайт стоит на первом месте. А теперь возьмем страницу с цитатами известного матерщинника:
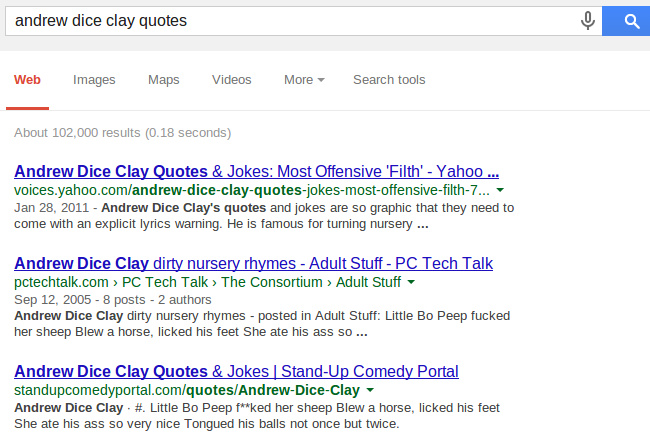
Топ-3 для поиска без фильтра.
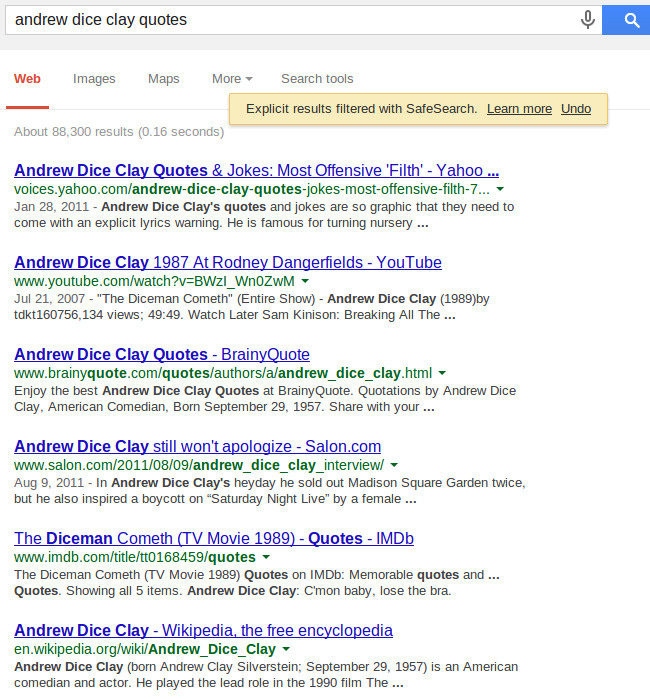
И отсутствие в выдаче с включенным фильтром.
Да, "стоп слова". Но какие они и сколько их? Понятно, что одним "fuck" дело не ограничивается...
Есть такой сайт, wdyl.com, один из сервисов Гугла, своего рода мета-поисковик (статья на вики). Если порыться в его исходном коде, то можно найти интересную АПИшку: wdyl.com/profanity?q=.
Проверка на profanity, т. е. Если мы подставим "стоп" слово (wdyl.com/profanity?q=fuck), то в ответ получим JSON, радостно сообщающий нам о том, что это есть обсценная лексика:
{"response": "true"}
Для wdyl.com/profanity?q=lol ответ будет false, естественно:
{"response": "false"}
Назвать это "багой" или недосмотром не поворачивается язык, скорее всего "фича", т. к. это АПИ широко известно в узких кругах не первый год. И что самое главное, спокойно держит любое количество запросов к нему с одного IP адреса.
Я решил проверить, какие слова данная тулза считает нехорошими. Для это я собрал все английские слова и проверил через это АПИ каждое из них. Ну, не все конечно. Всего в английском, если верить Оксфордскому словарю, порядка 250 тысяч слов без учета устаревших слов, технических терминов и сленга. А с учетом их уже под 600 тысяч.
Моя же база состояла из порядка 130 тысяч слов. Для начала, я спарсил все частотные таблицы из соответствующей подборки в википедии. И чтобы разбавить базу сленгом и прочим, спарсил также все цитаты со scomedy.com (порядка 15к) и весь bash.org. Полученную "текстовку" разбил на слова и почистил на дубли. А дальше - 130, 000 запросов к АПИ в один поток, что заняло больше 12-ти часов.
Список выявленных слов (в алфавитном порядке):
anal
anus
arse
ass
asses
asshole
assholes
balls
ballsack
bastard
beastiality
bestial
bestiality
biatch
bitch
bitches
bitchin
bitching
bloody
blowjob
blowjobs
boner
boob
boobs
breasts
bugger
bum
butt
butthole
buttplug
chink
clit
clitoris
cnut
cock
cockface
cocks
cocksucker
cocksucking
cok
coon
cox
crap
cum
cumming
cums
cumshot
cunnilingus
cunt
cunts
damn
dick
dickhead
dildo
dildos
dink
dinks
dogging
doosh
dyke
ejaculate
ejaculated
ejaculation
fag
faggot
fagot
fagots
fags
fanny
fatass
fcuk
feck
fellate
fellatio
flange
fook
fuck
fucka
fucked
fucker
fuckers
fuckhead
fuckin
fucking
fuckings
fucks
fuckwit
fudgepacker
fuk
fukkin
fux
gangbang
gaylord
gaysex
goatse
goddamn
goddamned
hell
heshe
hoar
homo
hore
horny
jackoff
jap
jism
jizz
knob
knobhead
kum
kummer
labia
lmfao
lust
lusting
masochist
masterbate
masterbation
masturbate
mofo
mothafucka
motherfuck
motherfucker
motherfuckers
motherfuckin
motherfucking
muff
mutha
muther
mutherfucker
nazi
nigga
niggah
niggas
niggaz
nigger
nob
numbnuts
nutsack
orgasm
pawn
pecker
penis
phonesex
phuck
phuk
phukking
pigfucker
piss
pissed
pisser
pissing
poop
porn
porno
pornography
pornos
prick
pron
pube
pussies
pussy
rectum
retard
rimming
sadist
schlong
screwing
scrote
scrotum
semen
sex
shag
shagging
shemale
shit
shite
shithead
shiting
shits
shitter
shitting
skank
slut
sluts
smegma
smut
snatch
spac
spunk
testicle
tit
tits
titties
tosser
turd
twat
vagina
viagra
vulva
wang
wank
wanker
wanky
whore
willies
willy
xxx
Сразу оговорюсь, что данный список слов всего лишь часть БД стоп-слов одного из сервисов Гугла. Другие сервисы могут использовать как и другие базы, так и совершенно иные алгоритмы по анализу. Например, в приведенном списке отсутствует слово "necrophilia", хотя основной поиск Гугла с включенным SafeSearch запрещает искать по нему. Аналогично и AdSense может иметь свой подход к анализу текстов. Сказать можно лишь то, что алгоритмы распознавания excessive profanity так или иначе коррелируют между собой, имея при этом ряд своих собственных особенностей.
Хотел также провести ряд тестов на предмет того, какая profanity является excessive, но не стал. Создать десять страничек с разной "тошнотой" нецензурных слов и посмотреть, какие из них зафильтруются, не сложно, конечно. Но это все будет вилами по воде, т. к. алгоритмы скорее всего много сложнее, чем простой подсчет процента встречаемости слов (наверняка считается и выделение обсценной лексики тегами, и их нахождение в тех или иных структурных блоках страницы, и частотное распределение, а не просто частота, и разный "вес" слов...). Т. е. какой-то процент "тошноты" я бы и получил, но вот применять его где-то на практике уже не получится, ибо цифра из воздуха, по сути.
Однако эксперимент на "общую корреляцию" все-таки провел. Взял страницу, заблокированную в SafeSearch поиске, и "пробил" ее на наличие слов по списку выше. Каждое найденное слово "запикал" (f**k, но можно и более "явно" - f*ck, sh*t и т. д., сработает в обоих случаях, проверил). После переиндексации страница стала доступна для поиска с включенным SafeSearch. Проверить наличие фильтра можно сравнив выдачу Гугла с включенным и выключенным фильтром SafeSearch, либо по запросу, по которому мы должны быть в топе, либо запросом наподобие site:site.com/page. "Включить" SafeSearch можно и GET параметром &safe=on, что актуально для парсинга (пока этим особо не занимался, но парсить "в лоб" file_get_contents() 'ом уже не получилось, HTTP request failed! HTTP/1.0 503 Service Unavailable и все такое).
Какую еще пользу можно получить с этого листа стоп-слов?
Если, например, делаем сайт для детей, то этих слов стоит, естественно, избегать (это и так понятно, но если вдруг на сайте есть форум или открыты комментарии - то здесь уже без модерации не обойтись, а в случае когда контент создается слишком часто уже поможет только автоматическая проверка).
А если делаем коммерческий сайт под АдСенс (к примеру, обзор кредитных организаций), где помимо авторского материала есть автоматически добавляемый контент с других сайтов (агрегация RSS лент) или UGC (отзывы на тот или иной банк), то проверяем все и вся перед публикацией на наличие стоп-слов. АдСенс за наличие нескольких нецензурных слов в комментарии, конечно, вряд ли забанит, но вот то, что начнет подсовывать центовые или вообще нулевые клики - скорее всего.
Или же если имеем крупный сайт. С десятками, сотнями тысяч страниц. Некоторые страницы не содержат нецензурных слов вообще, некоторые содержат, а некоторые так вообще состоят из того самого "чрезмерного" использования ненормативной лексики. Вешать на такой сайт АдСенс - большой риск. Но ведь хочется. Тогда поступаем просто - пишем ротатор рекламных объявлений, который анализирует содержимое страницы. Страница "чиста" - показываем АдСенс. Слишком много мата? Показываем рекламу более лояльного ко всему этому рекламодателя. Или вообще отключаем показ АдСенса на потенциально опасных разделах сайта, если это возможно.
Но да, стоит все-таки признать, что проблема больше касается развлекательных и UGC сайтов, причем в основном мелких и средних, без изначально продуманной "железной" бизнес модели, которые мало чем можно монетизировать помимо AdSense'а.
Вообще, суть всего поста можно сформулировать более коротко:
1. Страницы сайта, зафильтрованные Google SafeSearch - не лучшие претенденты для размещения на них AdSense.
2. Страницы, потенциально могущие попасть под этот фильтр - аналогично, лучше не стоит.
Или еще короче: если используем AdSense, то и выполняем его TOS. Однако это не всегда возможно, особенно в силу расплывчатости некоторых правил. Чего только стоят те же "excessive" и "intention". Хотя кого я обманываю, все всем понятно, конечно же. Но так уж получается.
Как пример, что я собираюсь делать с сайтом scomedy.com. Раньше писал, что по этому сайту вообще тоска-печаль, дескать под фильтр Гугла попал и без трафика остался, в АдСенсе сайт забанен, Читика никак себя не показывает. Но вроде постепенно все начинает налаживаться, из-под фильтра вышел и трафика получаю с поиска даже больше, чем в лучший месяц до фильтра, в АдСенсе успешно прошел апелляцию, получил инвайт в Media.net. Былой доход с него ($10+ дейли) еще не восстановил, но все к этому идет, догоним и перегоним, как говорится. Это все темы отдельных постов, а сейчас обратно к ненормативной лексике, что таки является проблемой сайта (наличие подборок цитат, многие из которых не блещут литературным английским).
Примерные планы моих дальнейших действий:
1. "Запикать" топовые нецензурные слова (в принципе, уже сделал, задело порядка 6-7% цитат).
2. Пробить весь контент по приведенному выше листу стоп-слов и удалить те материалы, которые не несут особой ценности и где явно перебор с нецензурщиной.
3. Проверить основные трафиковые страницы на предмет наложения SafeSearch фильтра и вывести их из-под него.
4. Понизить плотность использования ненормативной лексики на страницах за счет вывода большего количества контента. Хотя это больше не цель, а следствие, сейчас на странице с отдельной цитатой вывожу топ-10 цитат того же автора, но сделал я это для юзабилити, так что двух зайцев, получается.
5. Отказаться от размещения АдСенса на потенциально "плохих" страницах, особенно где ненужные слова могут попасть в тайтл, в пользу размещения рекламы от МедиаНет (опять же если взять страницы с отдельными цитатами, то основное содержимое у них это предложение-другое, откуда и дикая плотность ненормативной лексики даже при паре матерных слов, плюс первые несколько слов цитаты идут в тайтл, что усугубляет положение, страниц таких на сайте больше 15000 на данный момент, но трафика на себя они оттягивают около 10%, отказаться от размещения на них АдСенса будет более чем правильным решением).
6. Планомерно добавлять новые разделы и новый контент на сайт, максимально "чистые" с точки зрения АдСенса. Впрочем стоит признать, что я бы этим и так занимался, без оглядки на АдСенс. Хотя если вдруг появится форум, то я два раза подумаю, прежде чем повешу на него рекламу.
А так, если почитать TOS AdSense'а, то складывается впечатление, что рекламу можно размещать только на личном блоге о садоводстве, с авторскими фотографиями и закрытыми комментариями, т. к. даже кадр из фильма или скриншот игры являются де-факто нарушениями, не говоря уже о заимствованной картинке или размещении не своего ролика с Ютуба. Но, перефразируя всем известную шутку про законы, хорошо что строгость AdSense publisher policies компенсируется необязательностью их выполнения, особенно для премиум паблишеров.